GPT 논문 리뷰
GPT 논문 리뷰
1. Introduction
unlabeled text에서 word-level 이상의 정보를 얻는 게 쉽지 않음 이유 - 목적 함수를 알기 힘듬, 학습된 표상을 목표된 taks에 효율적인 전이 방법이 합의 되지 않았음. 그래서 준지도학습으로 접근하기가 어려움 => combination of unsupervised pre-training and supervised fine-tuning 대용량 코퍼스로 사전 학습 학습을 진행한 후 각각의 task에 맞는 adaptation을 시킬 것 (여기서는 BERT와의 차이점이 없는 건가?)
2. Related Work
- Semi-supervised learning for NLP 임베딩의 경우 단어 단위의 정보는 많이 포함하지만 상위 단위의 의미는 많이 포함하지 못함.
- Unsupervised pre-training 최근에는 이미지 분류, 음성 인식, 개체명인식, 기계번역에 사용 LSTM을 사용하는 사전 학습 과정이 어느 정도의 언어 정보를 포함하지만 짧은 범위의 예측 능력을 떨어뜨림 이러한 한계를 Transformer의 사용으로 극복하고자 함.
3. Framework
방대한 코퍼스로 마든 대용량 모형 학습 => labeles data 판별을 위한 fine-tuning
### 3-1 Unsupervise pre-training(비지도 사전학습)
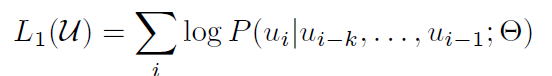
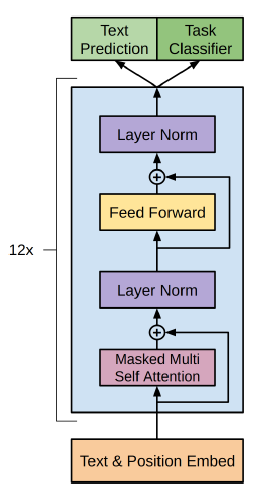
- multi-layer Transformer decoder
### 3-2 Supervised fine-tuning(지도 미세조정)
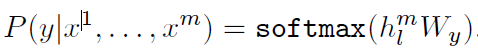
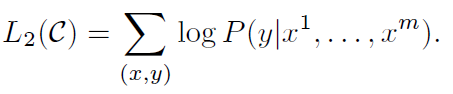
- 1~m까지의 단어가 주어졌을 때 y의 확률이 최대가 되는 것을 찾는다.
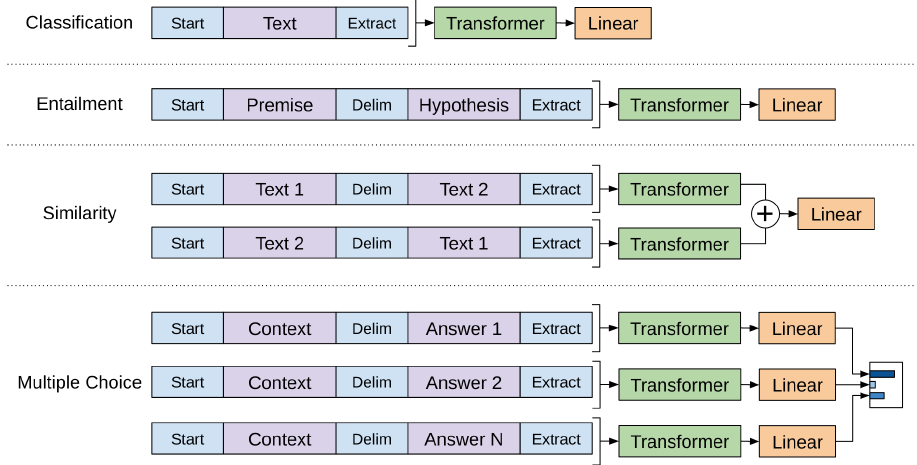
### 3-3 Task-specific input transformations
- traversal-style approach
## 4. 실험 ### 4-1 Setup ### Pre-train
- Dataset: BooksCorpus dataset, 1B World Benchmark
- Model
- layer decoder only transformr with masked self-attention head(768 dimensional states and 12 attention heads)
- FC 3072d, Adam optimizer(max lr 2.5e-4, lr was increased linearly for zero over the first 2000 updates & annealed to 0 using a cosine schedule.
- 100 epoches, mini batch size=64, max_seq_len = 512
- layernorm, BPE(vocab 40000), dropout=0.1
- L2 norm(w = 0.01), activation function = GELU
### Fine-tining
- 대부분의 작업에서 lr = 6.25e-5, batchsize=32, epochs=3, lr decay schedule(warmup over 0.2%, lambda = 0.5)
### 4-2 Supervised fine-tuning
- NLI, QA, Classification, Sementic Similarity, GLUE에서 많은 부분 SOTA 달성
## 5. Analysis ### 레이어 수가 많을수록 좋은 성능
- pre-train에서 각각의 레이어가 의미 있는 기능을 하는 것으로 보임
### Zero-shot (few shot) learning
- 가설: 생성적 모형은 언어 모델의 성능을 높인다. 많이 구조화가 되어 있을수록 유리
- finetuning이 필요 없는 모델을 만들고자 함.
- 계속 학습을 시키면 꾸준히 성능이 상승하는 것을 확인.
### aux LM
- 데이터셋이 작은 경우 Transformer의 aux LM을 제외하는 것이 성능이 좋았고 데이터셋이 큰 경우 full model이 성능이 좋음.
## 6. 결론
- GPT의 특징은 생성적 사전학습 모델과 파인튜닝
- 12개중 9개 부분 SOTA 달성