SBERT: Sentence-BERT for Sementical similarity comparison
> 새로운 질문이 주어졌을 때 기존의 질문들과 가장 유사한 질문을 얻기 위해서 어떤 방법을 사용해야 할까 고민하다가 도달한 논문입니다.
요약
siamese and tripet network structures를 이용해 semantically meningful sentence embeddings을 만들어 STS(semantic textual similarity) task와 같은 문장 간의 유사성을 구하는 task에 SOTA를 달성했다
1. Introduction
- BERT의 단점
1) 독립적인 sentence embeddings를 계산할 수 없음. model을 1번 거치고 나와야 고정된 사이즈의 embeddings vector를 구할 수 있음
2) poly-encoders는 score functi이 not symmentric하고 계산량이 너무 많음
2. 관련 연구
그동안 siamese BiLSTM을 이용하거나 Universal Sentence Encoder 등 Sentece embeddings에 대한 연구가 계속 진행되어 왔다
계산량을 줄이기 위해서 기존 BERT, RoBERTa 모델에 fine-tuning을 진행함
3. 모델

-
fixed sized sentence embedding을 만들기 위해 기존 BERT, RoBERTa의 모형에 pooling operation을 추가.
-
Using the output of the CLS-token, computing the mean of all output vectors (MEANstrategy), computing a max-over-time of the output vectors (MAX-strategy).
-
Classification Objective Function

- Regrssion Objective Function
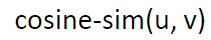
- Triplet Objective Function
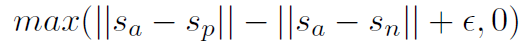
-
training dataset: SNLI(570,000 sentence pairs annotated with the labels contradiction, eintailment, neutral), Multi-Genre NLI(430,000)
-
batch-size=16, optimizer=adam, lr=2e-5, linear learning rate worm-up over 10% of the training data, default pooling=MEAN
4. 평가
4.1 Unsuperviese STS
- STS data를 이용하지 않은 모델

-
AVG GlOVE, BERT embeddings의 성능은 각각 61, 54, BERT CLS-vector는 29에 그침
-
SBERT모형이 기존 모형에 비해서 월등히 좋은 성능을 보이지만 SRoBERTa는 큰 차이가 없었음
4.2 Supervised STS
-
STSb를 이용하여 추가적인 학습을 진행
-
STSb로만 training을 진행한 것보다 NLI로 먼저 학습을 진행한 후 STSb로 추가 학습을 진행한 것이 1~2 points 높은 성능
-
오히려 BERT와 RoBERTa의 차이는 크게 없었음
4.3 Argument Facet Similarity

-
여러 주제에 대해서 동일한 주장인지 아닌지 0~5점으로 나타낸 AFS dataset에 대하여 평가를 진행
-
10-fold cross-validation에서는 BERT와 SBERT의 성능 차이를 보이지 않았지만 cross-topic evaluation에서는 SBERT가 7 points 정도 낮은 성능
-
BERT는 직접적으로 두 문장에 대한 비교를 하지만 SBERT는 독립적으로 sentence를 vector space에 mapping하기 떄문.
4.4 Wikipedia Sections Dintinction
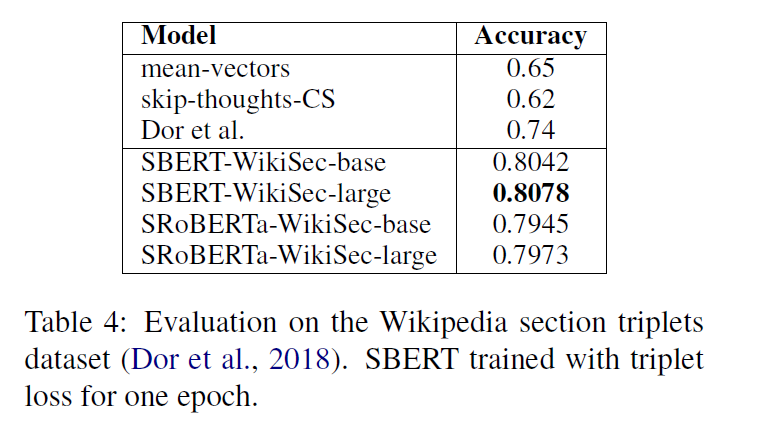
5. Evaluation -SentEval
- SBERT가 다른 작업에 대한 전이학습의 목적으로 만들어진 것은 아니지만 좋은 성능을 보여줌
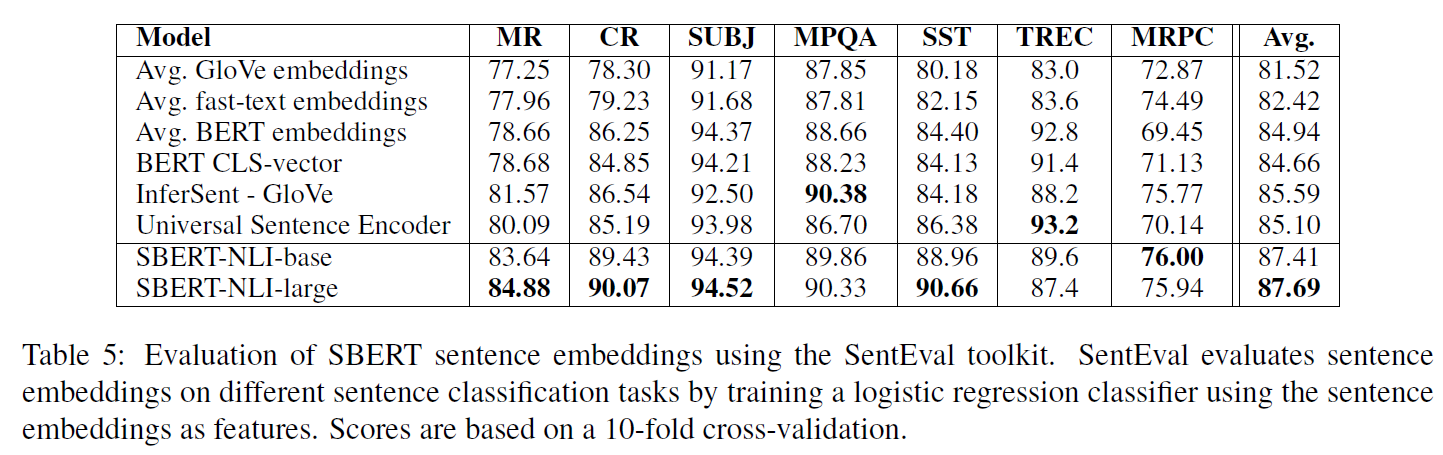
-
SBERT의 setence embeddings가 감정 정보를 잘 포착함
-
avg BERT emb나 CLS-token output은 코사인 유사도를 사용할 수 없는 문장 임베딩을 만든다는 결론
-
하지만 NLI dataset으로 fine-tuning을 하면 SentEval에서 좋은 성능
6. Ablation study

7. Computational Efficiency

8. 결론
BERT의 임베딩을 그대로 사용하는 것은 문장의 표현으로 적절하지 않고 해당 연구처럼 siamese / triplet network architecture으로 fine-tuning한 해당 모델이 문자의 비교에 좋은 성능을 보임