[논문리뷰] T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Abstract
모든 텍스트 기반 언어 문제를 text-to-text 형태로 바꾸는 통합된 프레임워크를 도입
체계적인 실험을 통해서 사전학습 목적함수, 아키텍쳐, unlabeled data sets, 전이 구조 등 다양한 요소들에 대한 비교 진행
1. Introduction
- 최근 대용량 데이터를 이용해 NLP 모델에 pre-train을 진행하는 것이 일상화 됨
- Common Crawl project를 통해 한 달에 20TB의 데이터가 수집되고 이를 이용하면 모델의 크기를 극대화할 수 있음
- 더불어 전이학습 과정에서 사전학습 목적함수, 데이터셋, 벤치마크, 파인튜닝 방법 등이 너무 다양해져 다른 알고리즘 간의 비교가 어려워짐
- 이러한 문제점을 해결하기 위해 모든 텍스트 문제를 text-to-text 문제로 바꾸어 학습시키는 방법을 도입
- text-to-text 프레임워크을 통해 task마다 같은 모델, 목적함수, 학습 과정, decoding 과정을 적용할 수 있게 만듬
- 논문의 목표는 새로운 방법을 제시하려는 것이 아닌 NLP field에 대한 포괄적인 관점을 제시하기 위한 목적
2. Setup
2.1 Model
- T5의 model은 기존의 encoder-decoder Transformer와 거의 유사
- 기존 트랜스포머와 차이점
1) Layer Norm bias 제거- b 제거
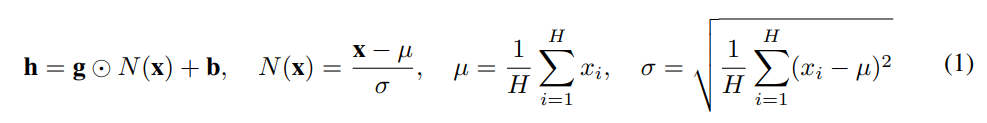
2) layer normalzation을 residual path 밖으로 기존 트랜스포머는 skip connection 진행 후 layer normalization을 실행했다면 T5는 layer normalization을 먼저 실행
cf) transformers - BERT model
transformers - T5 model
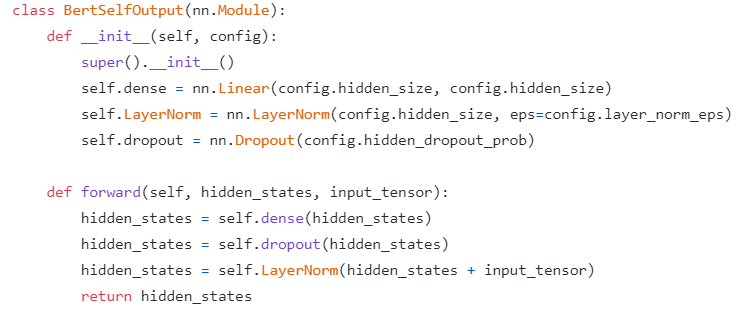

3) relative position embeddings 사용 기존의 BERT model에서는 sinusoidal position 임베딩을 사용했다면 최근의 추세에 맞춰 relative position embeddings 사용 & 모든 레이어에 동일한 position embeddings 공유
cf) Relative Position Encoding
BERT의 경우 sequence length가 512일 때, 0~511까지 sequence id를 통해 embedding을 통과. 이 때 각 위치의 vector값들은 항상 동일한 값. 이를 보완하기 위해 relative position representation은 각 token의 상대적인 위치를 나타냄.

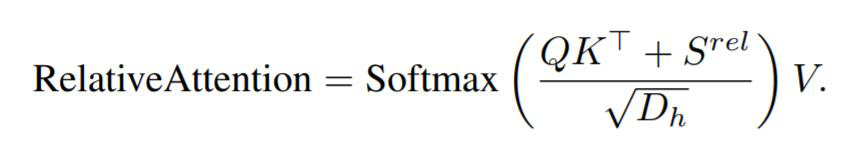
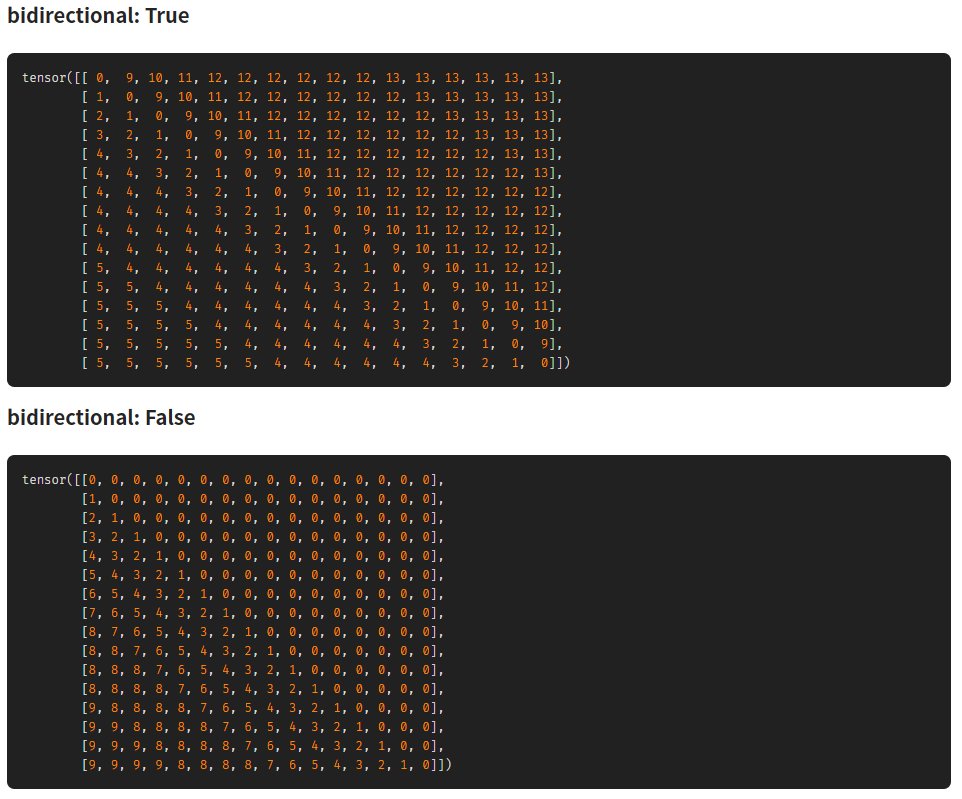
- Cloud TPU Pod를 이용해서 모델과 데이터를 병렬 처리 1024개의 TPU v3, Mesh TensorFlow library 사용
2.2 Dataset
- Common Crawl로 수집된 2019년 4월 데이터 20TB를 정재 과정을 거쳐 750GB의 C4 데이터셋 제작
2.3 Downstream Tasks
- 다운스트림 퍼포먼스 연구를 위해 사용한 벤치마크 1) GLUE, SuperGLUE for Classification 2) CNN/Daily Mail for abstractive summarization 3) SQuAD for QA 4) WMT English to German, French, and Romanian for translation
2.4 Input and Output Format
- pre-train, fine-tuning 모두 maximum likelihood objectives를 사용
- task 구분을 위해서 task-specific text prefix 사용 ex) input: STSB sentence1: ~~
- classification task의 output이 원하는 형태 (ex MNLI의 경우 entailment, contradiction, neutral)가 아닌 경우 전부 틀렸다고 여김
- Regrssion의 경우 (ex STSB) 1~5의 label을 0.2 단위의 class로 변경해 21개의 class를 분류하는 task로 변화
-
문장에서 대명사가 가르키는 것을 찾는 Winograd Task는 예시처럼 **으로 표시
ex)
“The city councilmen refused the demonstrators a permit because they feared violence.”
3. Experiments
Baseline model을 만들고 다양한 변종 모델을 만들어가면서 성능을 비교
pre-training objectives, model architectures, unlabeled data sets 등에 대한 실험을 진행
3.1 Baseline
3.1.1 MODEL
- 기본적인 encoder-decoder 형태와 다른 모델의 형태를 비교
- 따라서 baselined model은 BERT BASE와 유사하게 구성 dff = 3072, dkv = 64, dmodel = 768 ⇒ 약 220M parameters
3.1.2 Training
- standard maximum likelihood를 이용해 학습
- Optimizer = AdaFactor
- max_seq_len = 512, batch size = 128 여러 개의 문장을 하나의 배치로 합쳐서 사용 배치마다 = 2^16 = 65536 tokens 포함
- pre-train step = 2^19 = 524288
-
total pre-traing on 2^35 = 34B tokens BERT = 137B, RoBERTa=2.2T
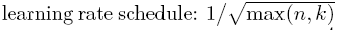
- warm-up steps = 10000
- Finetune 모든 task에 2^18 = 262144 steps lr = 0.001, max_seq_len = 512, batch size = 128 5000 steps/checkpoint
3.1.3 Vocab
- SentencePiece 사용
- 번역 task를 위해 Multilngual Vocab size = 32000
3.1.4 비지도 목적함수
- 최근에는 masking한 token들을 예측하기 위해 학습이 되는 모델에 사용되는 denoising 목적함수(Masked language model)를 많이 사용
-
T5도 기본으로 BERT style의 obejectives 채택.
BERT와 동일하게 15% drop out, 드랍된 span은 하나의 sentinel token으로 대체

3.1.5 Baseline Performance

- 신뢰구간을 구하기 위해 Baseline model을 from scratch로 10번 학습을 진행하고 성능을 평가
- pre-train의 성능을 평가하기 위해 pre-train을 진행하지 않은 모델과 해당 모델을 동일하게 2^18 stops 만큼 fine-tuning을 진행해 성능 비교 ⇒ 당연하게도 pre-train model의 성능이 뛰어남, 하지만 번역 모델에서는 큰 차이 없음
- 모든 모델을 여러번 학습시킬 수 없어 해당 신뢰구간을 다른 실험에도 똑같이 적용
- 표준편차는 대부분이 1보다 작았지만 샘플 수가 엄청 작은 task는 조금 더 크게 나오기도 함
3.2 Architectures
3.2.1 Model Structures
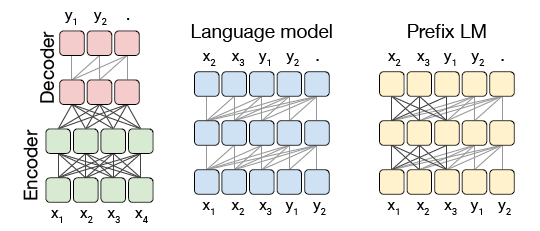
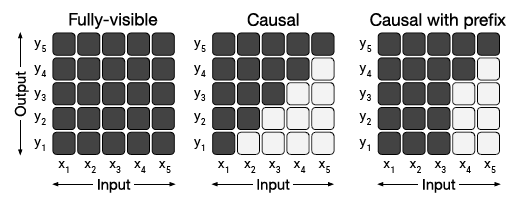
- 첫번재 구조는 흔히 보는 인코더 디코더 트랜스포머 인코더는 fully-visible attention mask를 사용하고 디코더 casual masking을 사용. 모델은 next-step을 예측하기 위해 학습
- Language model은 경량화 혹은 sequence generation을 위해 사용 text-to-text task에서는 prefix를 사용해서 “translate English to German: That is good. target:”을 input으로 사용 이러한 구조는 인코더와 디코더의 파라미터를 공유하는 모델과 유사한 형태
결과
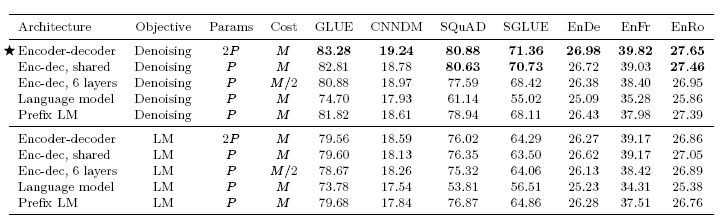
- 디노이징 목적함수를 사용한 인코더 디코더 아키텍쳐가 가장 좋은 성능
- 인코더와 디코더의 파라미터를 공유하는 모델은 파라미터는 절반이지만 거의 유사한 성능
- 목적함수도 LM objective보다 Denosing objective가 훨씬 우수
3.3 Unsupervised Objectives
아래와 같은 탐색 진행
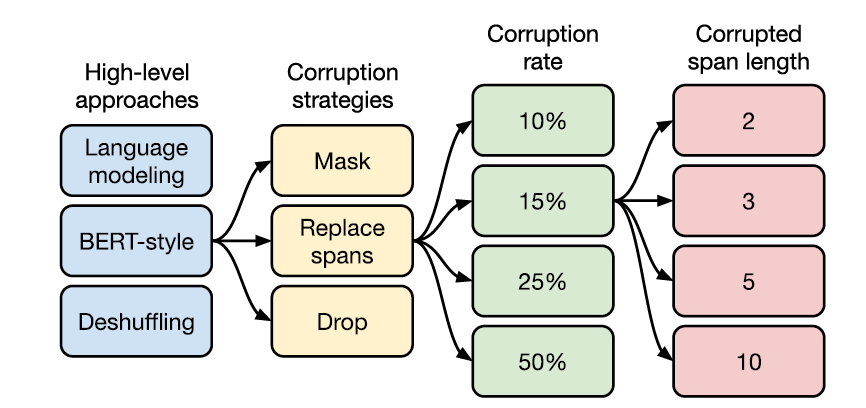

이후에 나오는 각 objective의 실제 적용 예시
3.3.1 Disparate High-Level Approaches

- 앞에서도 비교했던 prefix language modeling과 BERT-style(Denosing objective), Desuhffling 비교 prefix language modeling은 특정한 부분까지 제시하면 다음부분을 예측하는 방식 BERT-style은 masking을 해서 원래의 문장을 찾는 방식 Deshuffling은 순서를 섞어서 원래 문장을 찾는 방식
- 결과는 BERT-style이 모든 task에서 좋은 성능
3.3.2 Simplifying the BERT Objective

- BERT는 인코더만 있는 모델이기 때문에 인코더-디코더 모델에 맞는 적절한 변형이 필요
- BERT에서 15%의 [MASK] 중에 일부를 랜덤토큰으로 바꿔주는 과정이 있는데 해당 부분 제거 - MASS style 변형된 span만을 예측하는 방법 - replace span input에서 마스킹된 부분을 drop하는 방법 - Drop tokens
- 큰 성능의 차이는 없었으나 Replace 혹은 drop을 하면 Target이 짧아져 학습이 빨라진다는 장점이 있고 Drop은 문법성을 확인하는 task인 COLA에서 두드러지게 좋은 모습을 확인
3.3.3 Varying the Corruption Rate
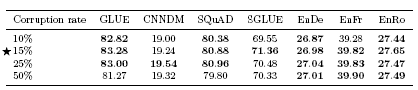
- token을 corruption하는 비율은 성능에 큰 영향을 주지 않았으나 50%까지 corruption을 하는 경우 성능이 떨어지는 것을 확인
3.3.4 Corrupting Spans
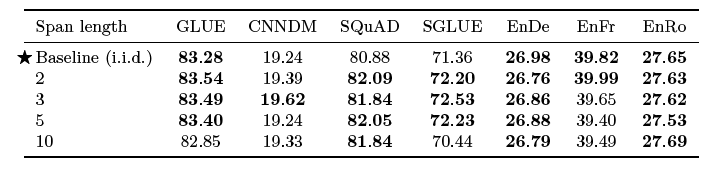
- 독립적인 corruption vs span corruption(spanBERT) 독립적인 corruption은 작은 span을 여러 개, span corruption은 큰 span을 적은 수로 진행해 sapn이 target 수가 줄어들기 때문에 더 빨라진다는 장점
- sapn length를 3으로 했을 때 작지만 유의한 성능 향상을 확인
⇒ denosing objective에 다양한 변형을 시도해봤지만 큰 변화는 없었음
3.4 Pre-training Data set
- 데이터셋에 따른 성능 차이 비교
- 사용된 데이터셋 C4: 필터링 진행한 C4 데이터 Unfiltered C4: 필터링 진행하지 않은 C4 RealNews-like: C4에서 뉴스만 선택 WebText-like: C4에서 레딧 추천글만 선택 Wikipedia Wikipedia+Toronto Books Corpus(BERT)
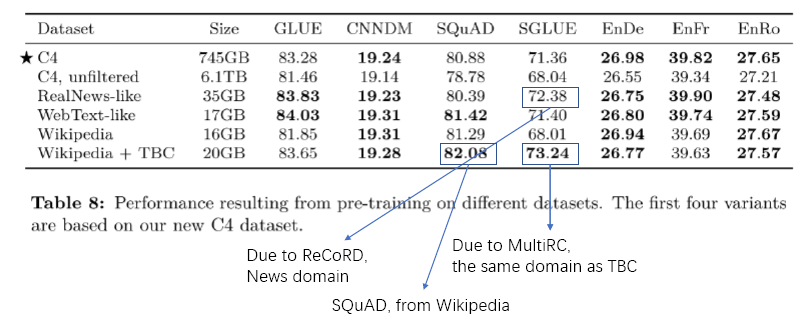
- 특정 도메인에 대한 데이터를 학습시켰을 때 해당 downstream task에서 우수한 성능
3.4.2 Pre-training Data set Size
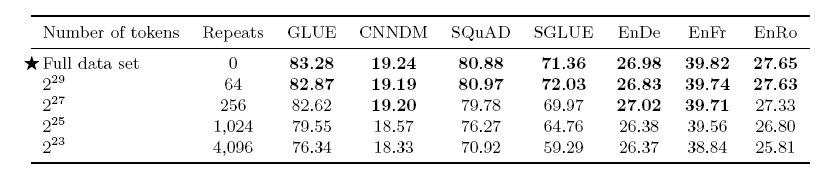
- Dataset size가 클수록 좋은 성능
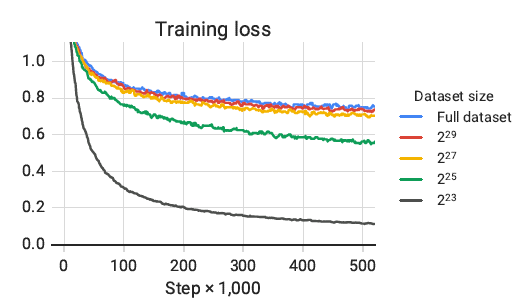
- Training loss를 봤을 때 같은 데이터를 여러번 학습시키는 것도 성능 향상이 있음을 확인
- 가능한 많은 데이터를 사용하는 것이 좋고 모델이 큰 경우 더욱 분명하게 데이터가 커야 좋다는 것을 확인
3.5 Training Strategy
3.5.1 Fine-tuning Methods
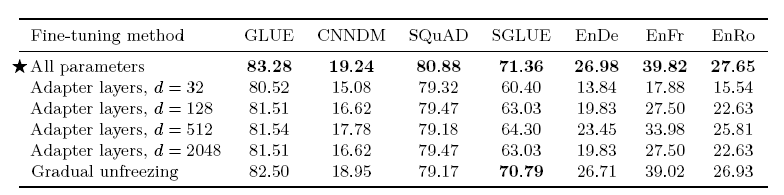
- 모든 파라미터를 업데이트하는 방법과 다른 2가지의 fine-tuning 전략 비교
1) Adapter layers: 파인튜닝 과정에서 기존 모델에 추가적인 레이어를 달아서 그 레이어만 학습 진행. dense-Relu-dense blocks 추가. adapter layer와 layer normalization 파라미터만 업데이트.
2) gradual unfreezing: 파인튜닝을 시작할 때는 마지막 레이어만 업데이트하고 일정한 업데이트가 진행되면 순차적으로 나머지 레이어의 업데이트도 진행. 2_18/12 stpes마다 학습 레이어 추가
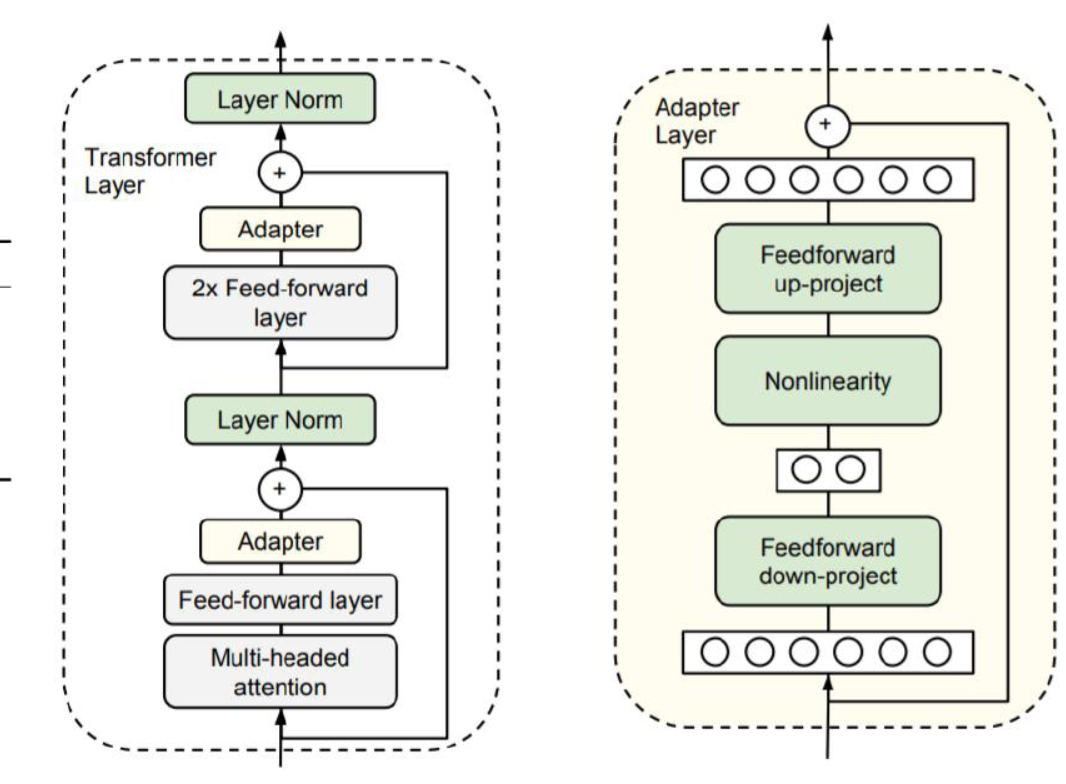
- SQuAD와 같은 리소스가 적은 task에서는 d가 작아도 괜찮은 성능, higher resource task에서는 더 큰 d가 필요
- gradual unfreezing은 일정한 부분의 성능 하락이 있어지만 속도가 빨라진다는 장점이 있음. 더 좋은 결과를 위해서는 더 섬서헤나 scheduling이 필요
3.5.2 Multi-task Learning
- pre-train 과정에서 다양한 task에 대해서 동시에 학습 진행
-
모델이 각각의 task의 data를 얼마나 학습하는지가 중요. task마다 under or over-train이 없어야 함 1) Example-proprtional mixing 각각의 task의 data set size만큼의 sample 비율로 학습시키는 것 이 좋음. task마다 datset size가 다르므로 인공적인 limit을 지정
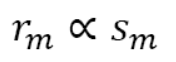
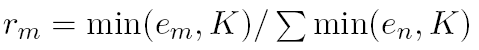
2) Temperature-scaled mixing multilingual BERT에 사용된 방법. 자료가 적은 언어에 대해서도 충분히 학습시키는 방법. K=2^21 사용. 큰 수의 K를 사용해 가장 큰 데이터셋의 포함 비율을 낮춤.
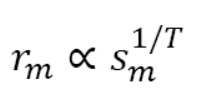
3) Equal 동일한 비율로 sampling. 자료가 적은 task에 over-train.
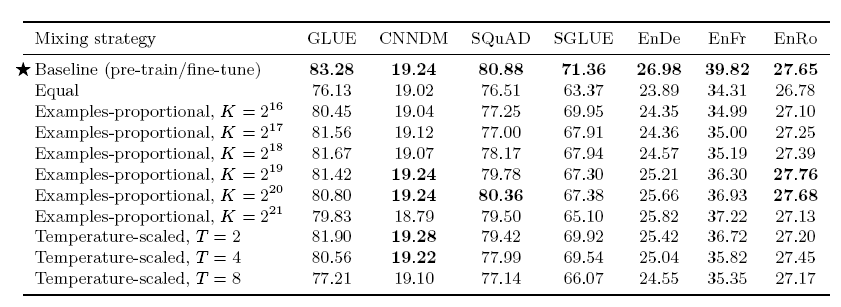
- 대부분의 multi-task training에서 성능이 떨어짐. 특히 equal에서 자료가 적은 task에 심각한 overfit이 발생해 심각한 성능 하락이 발생.
3.5.3 Combining Multi-Task Learning with Fine-Tuning
- ‘MT-DNN’에서 사용된 방법 도입. 모든 task를 한번에 pre-train을 진행하고 각각의 지도학습 task마다 fine-tuning 시키는 방법 1) 각각의 fine-tuning task에 대해서 pre-train과 fine-tuning 진행. K=2^19 2) leave-one-out: 특정 task에 대해서 pre-train에서 제외하고 그 task에 대해서 파인튜닝 진행. 실제 환경과 유사하게 3) 모든 task에 대해서 Example-proprtional mixing에 따라 모두 pre-train 진행

- multi-task pre-training을 진행하고 fie-tuning을 진행한 것이 baseline에 필적할만한 성과를 보임. superviese multi-task이 다른 task에서는 낮은 성능을 보였으나 번역 task에서는 좋은 성능을 낸 것으로 보아 English pre-training이 번역 task에는 큰 도움이 되지 않음을 확인
3.6 Scaling
- 일반적으로 scaling up을 하면 모델의 성능 향상 더 큰 모델, 더 많은 학습 스텝, 앙상블 등의 방법
- 앙상블 제외하면 모두 4배의 계산량이 있는 모델을 비교 독립적으로 pre-train과 fine-tuning을 진행한 4개의 모델을 앙상블한 모델과, 동일한 pre-trained model에 각각 파인튜닝을 진행한 모델을 앙상블한 모델: 모두 output softmax에 들어가기 전에 logits을 평균
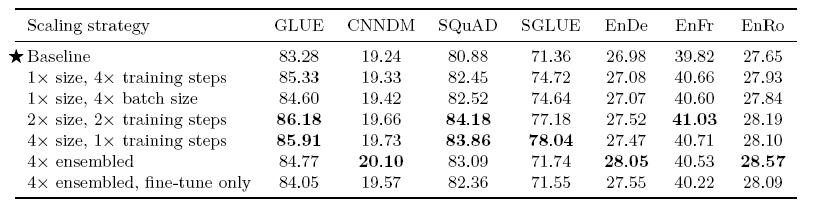
- 모델 사이즈와 학습 시간을 늘리는 것은 성능 향상에 도움을 줌 앙상블 또한 효과적인 성능 향상법 큰 모델을 사용하면 파인튜닝과 추론 비용이 커지고 작은 모델을 오래 학습시키면 그 부분에서 이점을 얻을 수 있음
3.7 Putting It All Together
앞에서의 실험을 바탕으로 좋은 성능의 모델을 제작
1) Objective span-corruption bjective, span length of 3 and corrupt 15%
2) Longer training C4 데이터셋이 크기 때문에 충분한 학습을 진행해야 함 train steps = 1M, batch size=2048, seq_lenth=512 ⇒ 1T tokens 베이스라인의 32배
3) Model sizes
Base = 220M, dmodel=768, dff=3072, dkv=64. head=12, layer=12
small = 60M, dmodel=512, dff=2048, head=8, layer=6
Largel = 770M, dmodel=1024, dff=4096, head=16, layer=24
3B = 2.8B, dmodel=1024, dff=16384, dkv=128, head=32, layer=24
11B = 11B, dmodel=1024, dff=65536, dkv=128, head=128, layer=24
4) Multi-task pre-training: ‘MT-DNN의 Multi-task pre-training 도입
5) Fine-tuning on individual GLUE and SuperGLUE tasks: GLUE, SuperGLUE 벤치마크 전체에 대하여 한번씩 fine-tuning 진행
나머지 하이퍼파라미터는 base와 동일
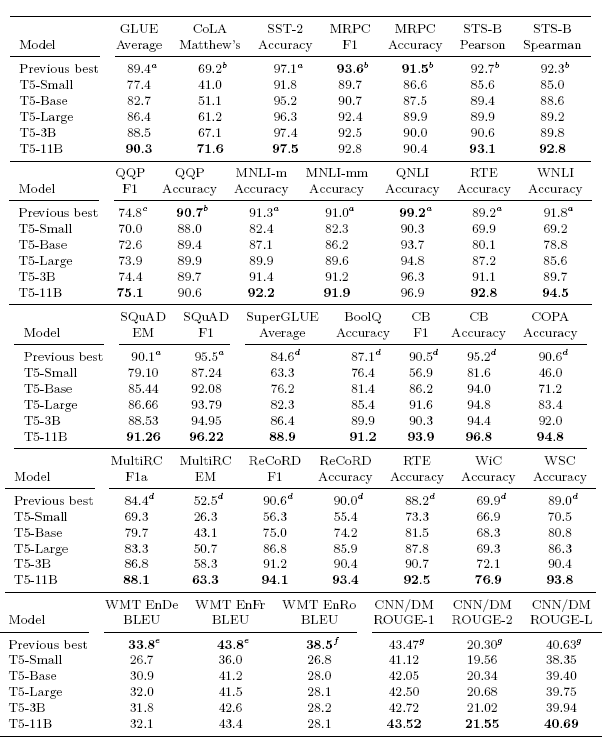
- 24개의 task 중 18개에서 SOTA 달성
- GLUE에서 눈에 띄는 성능 향상. SOTA를 달성하지 못한 task는 ALBERT model 6~17개를 앙상블한 모델
- SQuAD 및 SuperGLUE에서는 압도적인 성능
- 번역 task에서는 하나도 SOTA를 찍지 못함. 레이블이 없는 영어 데이터만 학습했기 때문에. 최근에 많이 사용하는 역번역도 사용하지 않음

- Baseline, 사이즈를 키운 Baseline-1T, Baseline-1T와 사이즈가 동일하지만 앞의 실험 결과를 적용한 T5-Base 성능을 비교했을 때 T5-Base가 월등히 성능이 좋음 실험 결과가 유의미 했음을 알 수 있음
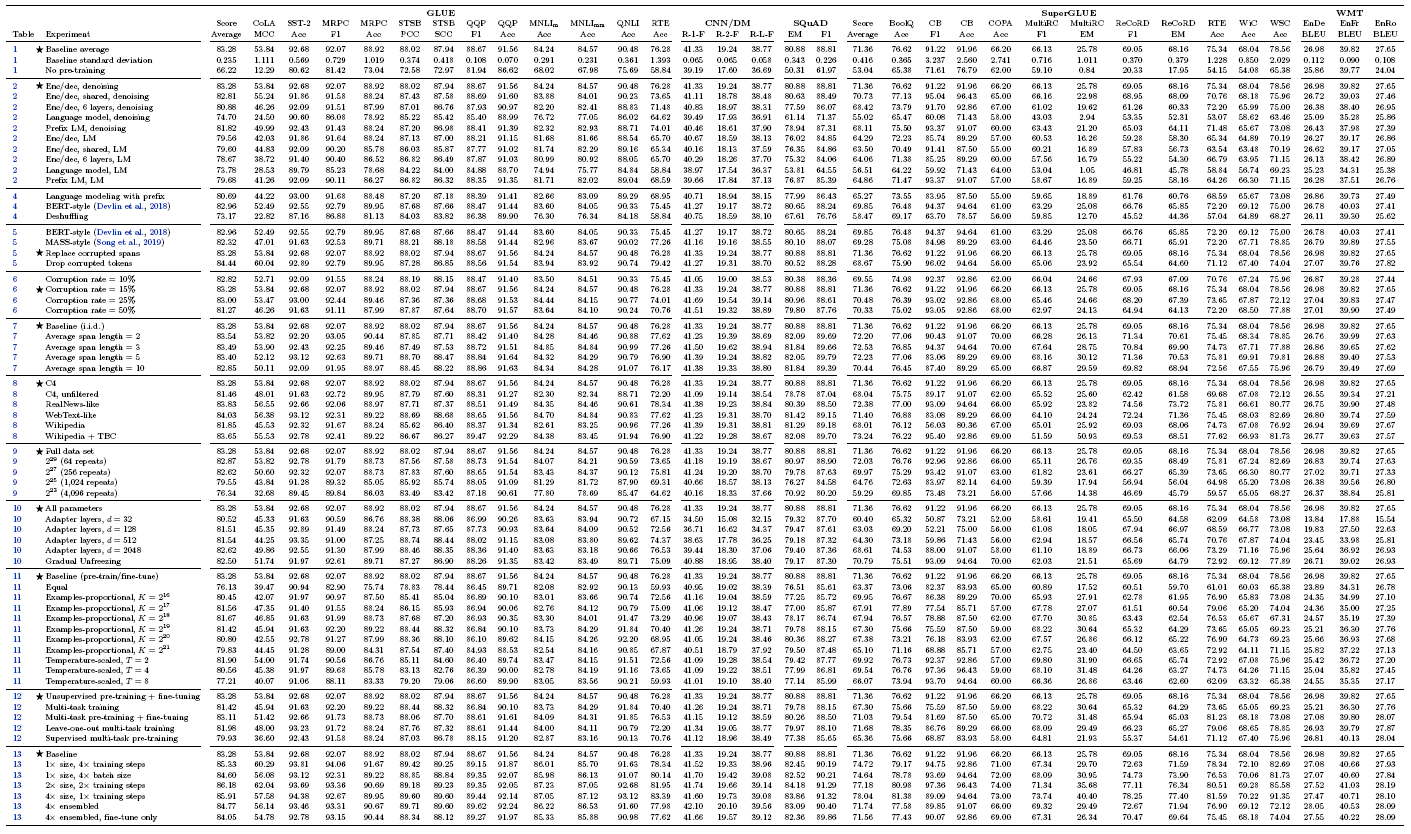
종합
- Text-to-Text 프레임워크를 이용해 다양한 pre-train, fine-tuning 기법들에 대해 실험을진행해 SOTA model 제작
- MASS, MT-DNN, mBERT 등 발전되고 있는 다양한 기법을 실험에 적용
- 방대한 양의 실험을 진행한 것이 경이로움
- 이 논문을 통해 최근 전이학습 방향성 이해에 큰 도움이 되었음
- 언어모델에서도 앙상블을 사용하는 것이 인상적